Automate the deployment, migration, and configuration of large Cisco Meraki infrastructures, and streamline overall network administration.
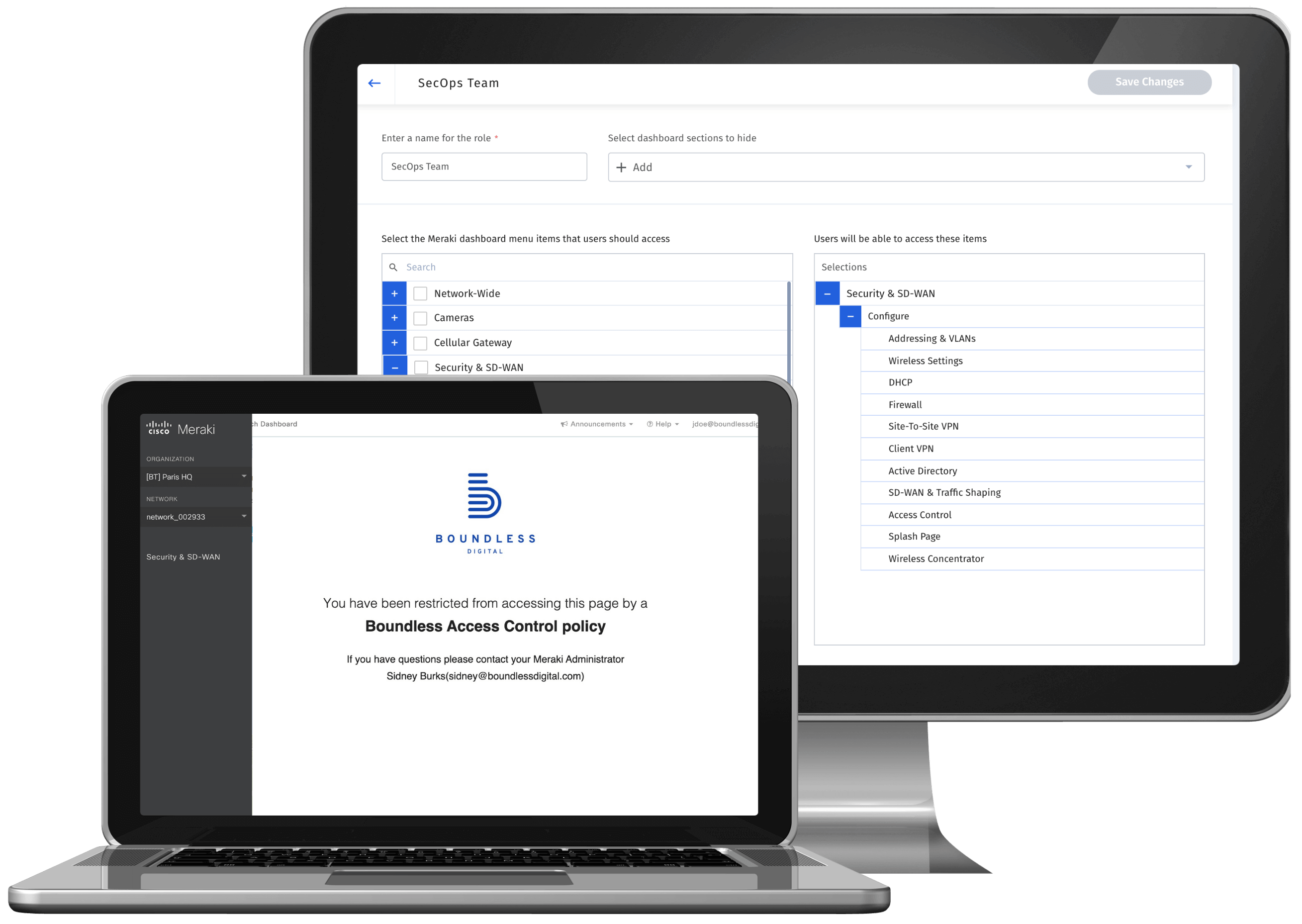
Role-based Access Control
Create custom and granular access levels to the Cisco Meraki dashboard. Manage user membership across hundreds of organizations in bulk.
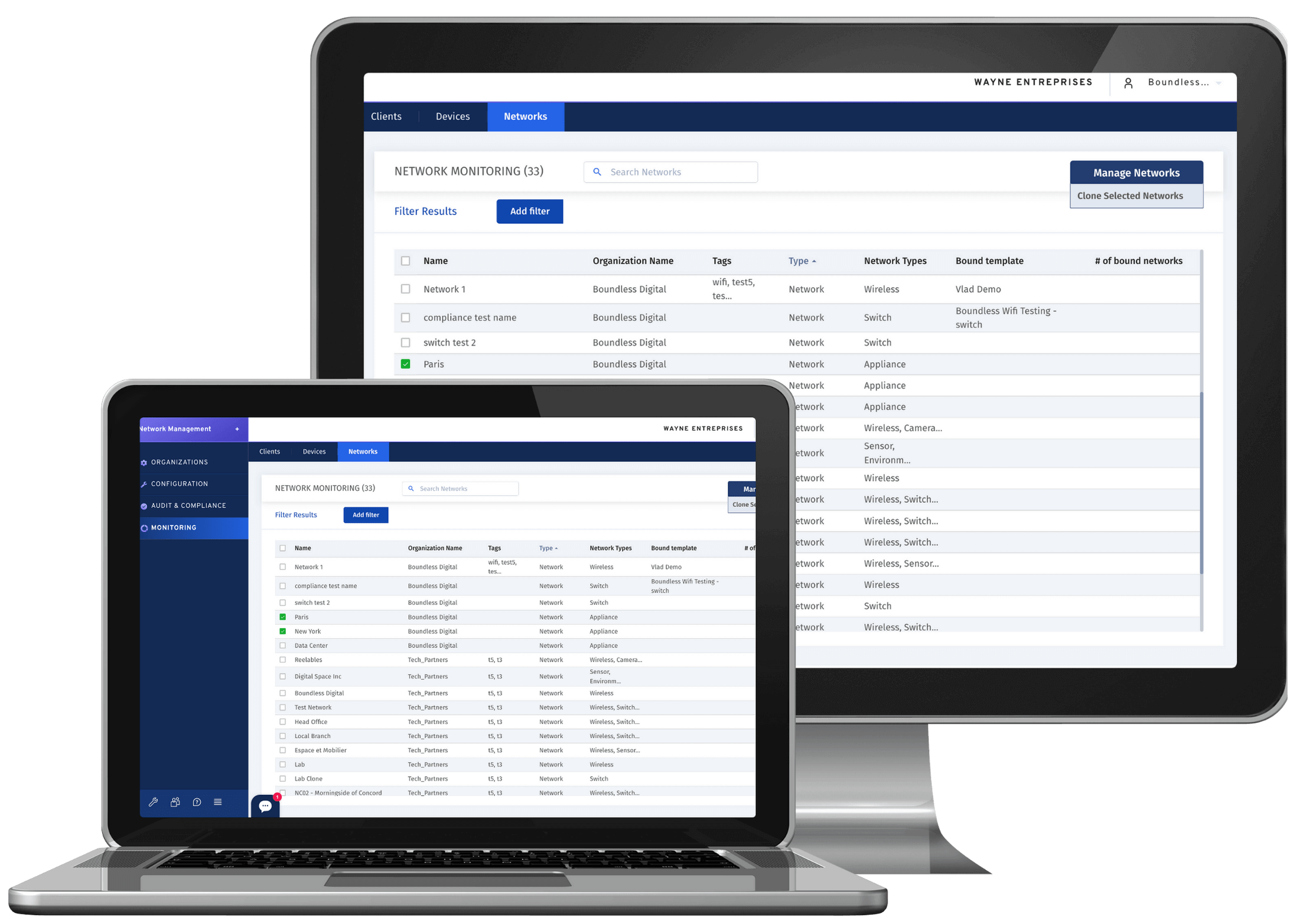
Batch Network Provisioning
Ensure consistency across your networks and minimize the risk of human error by deploying and provisioning hundreds of Meraki networks in bulk.
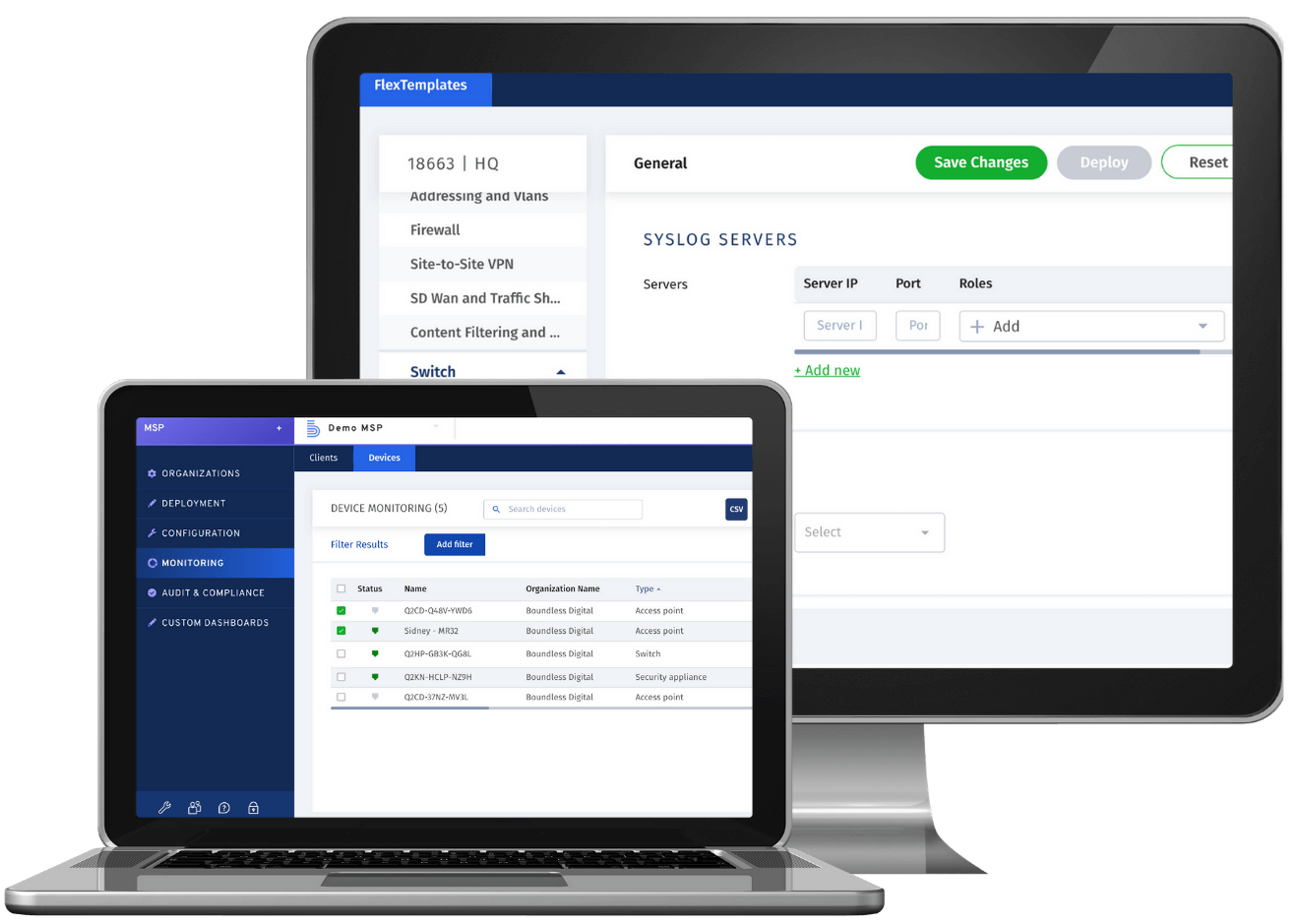
Network and Device Migration
Migrate your networks and devices across Meraki organizations more easily, with less errors, and in a fraction of the time.
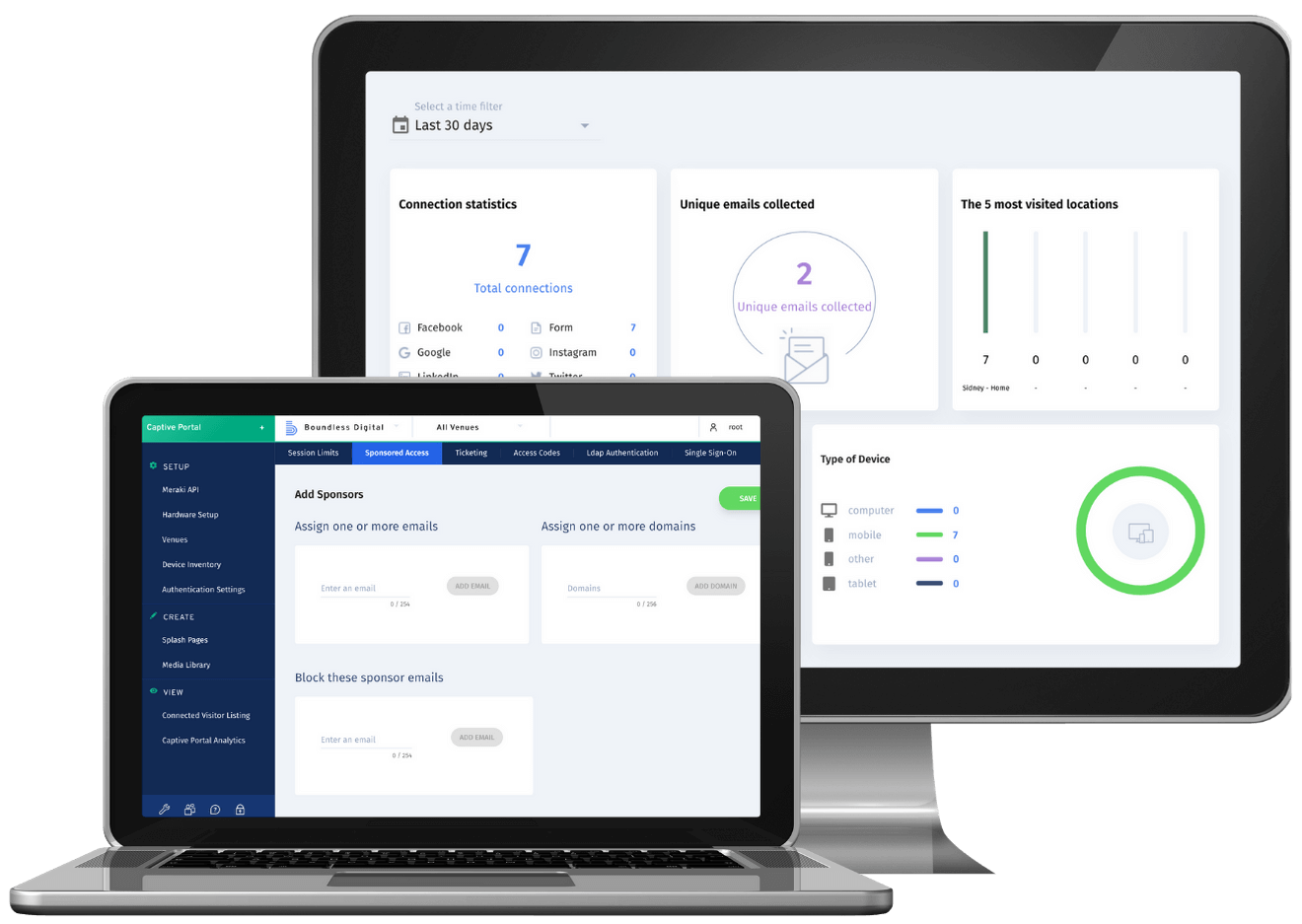
Guest WiFi Management
Easily configure and manage your public WiFi network across multiple sites. Create nice-looking captive portals with a wider variety of sign-on methods.
Easily configure and manage your public WiFi network across multiple sites. Create nice-looking captive portals with a wider variety of sign-on methods.
The Boundless Apps optimize the management of large Meraki infrastructures thanks to API-driven automation. Our solutions increase your team’s efficiency, reduce the risk of human error and improve the compliance of your networks.
For Production Teams
Are you managing multiple client organizations? The Boundless Apps centralize all your managed organizations within one single dashboard and let you perform operations at scale through to the use of the Meraki API. This can help you cut down operational costs and increase your overall productivity.
For Operations Teams
If your team is responsible to deploy new Cisco Meraki infrastructures, our solutions will help you accelerate your operations and keep your networks standardized.
For Network Engineers
The Boundless Apps optimize the management of large Meraki infrastructures thanks to API-driven automation. Our solutions increase your team’s efficiency, reduce the risk of human error and improve the compliance of your networks.
For Production Teams
Are you managing multiple client organizations? The Boundless Apps centralize all your managed organizations within one single dashboard and let you perform operations at scale through to the use of the Meraki API. This can help you cut down operational costs and increase your overall productivity.
For Operations Teams
If your team is responsible to deploy new Cisco Meraki infrastructures, our solutions will help you accelerate your operations and keep your networks standardized.
Driven to provide top-notch service and support.
When working with Boundless, what I appreciated the most is the amount of time that it saved us. And what I appreciate the least… There is nothing I can really say. It was a tool that worked well for us. We will hopefully be able to use it again.
They do everything they can to get their product to do what we ask. I haven't seen any product as well polished in recent years that we've tested, or that add so much of a quality of life improvement to working with Meraki networks.
Craig B.
Lead Automation Engineer
They have built a nice UI and are continuing to develop and add more features. Their support is great and their pricing is reasonable. I look forward to continue working with them in the future.
Shaun D.
Data Network Engineer
The Boundless Digital solution is complementary to the Meraki offer (...).
It allowed us to free up a lot of engineering time, which we can use to develop new services.
Thibault C.
Network Architect
Today Boundless is really leading Network automation. (...) With Boundless Digital and Meraki APIs you can drive efficiency and cost-savings.
Leo F.
Solution Architect
When working with Boundless, what I appreciated the most is the amount of time that it saved us. And what I appreciate the least… There is nothing I can really say. It was a tool that worked well for us. We will hopefully be able to use it again.
They do everything they can to get their product to do what we ask. I haven't seen any product as well polished in recent years that we've tested, or that add so much of a quality of life improvement to working with Meraki networks.
Craig B.
Lead Automation Engineer
They have built a nice UI and are continuing to develop and add more features. Their support is great and their pricing is reasonable. I look forward to continue working with them in the future.
Shaun D.
Data Network Engineer
Learn how Boundless solutions
have already helped business like yours.